
The Model Lock-In Problem:
How to Architect AI Agents So You Can Actually Switch Providers

The Question That Should Keep You Up at Night
You’ve built an AI agent. It works. It’s handling customer inquiries, processing documents, routing tickets, drafting proposals — whatever the use case. You picked a model from one of the major providers, tuned your prompts, wired up your tools, and shipped it.
Then six months later, one of three things happens:
1. A competitor releases a better, cheaper, or faster model and you want to switch.
1. Your current provider raises prices, deprecates the model you depend on, or has an outage.
1. Your provider releases a new version of the same model and your agent quietly starts behaving differently.
You go to swap models — or the swap happens to you whether you wanted it or not — and discover that your carefully tuned agent now produces different outputs. Sometimes subtly different. Sometimes catastrophically different. And you find out in production, from your customers, after the damage is done.
This is the **model lock-in problem**, and it is one of the most under-discussed risks in AI implementation today. Most companies discover it the hard way.
There is a better way. It’s not a silver bullet, but it transforms model portability from “we’ll find out when it breaks” into “we caught the regressions in eval before shipping.” That’s the difference between professional and amateur AI deployment.
What This Post Covers
This is a practitioner’s guide to architecting AI agents for portability across model providers. We’ll cover:
- Why behavioral drift between models is real and unavoidable
- The two-layer architecture that makes portability possible
- The evaluation harness that catches regressions before they ship
- Operational practices: prompt versioning, structured outputs, canary deployments
- An honest accounting of what this approach can and cannot do
If you’re running AI in production, or planning to, this is foundational infrastructure. Skip it at your peril.
Why This Problem Is Harder Than It Looks
The naive view is that swapping models is a configuration change. Change one line, point at a different API endpoint, you’re done. This is wrong in three different ways.
**First, the APIs are not interchangeable.** Anthropic, OpenAI, Google, and the open-source providers all have different request formats, different ways of handling system prompts, different tool-calling schemas, different token limits, different streaming protocols, different error semantics. Code written against one provider’s SDK does not run against another’s without translation.
**Second, the models themselves behave differently.** This is the one that bites people. Two models given the exact same prompt will produce different outputs. Sometimes the differences are cosmetic — tone, verbosity, formatting. Sometimes they are operational — one model follows your instructions strictly, another paraphrases them. Sometimes they are dangerous — one model calls the correct tool with the correct arguments, another hallucinates an argument that doesn’t exist or skips the tool call entirely.
**Third, even within the same provider, models drift.** Provider releases a new version. Provider silently updates the model behind a stable name. Provider deprecates the version you were using. Your agent’s behavior changes and you didn’t change anything.
A portable architecture has to address all three.

The Two-Layer Architecture
The core pattern is separation of concerns: keep your agent logic completely independent of any specific model provider. You do this by introducing an abstraction layer — call it a **model gateway** or **LLM router** — between your agent and the underlying API.
Layer One: The Agent
The agent contains your business logic. It knows what task it’s trying to accomplish, what tools it has available, what the conversation state is, what the user is trying to do. It does not know — and does not care — which model is generating the responses.
The agent calls an internal interface that looks something like:
```
response = llm.complete(
prompt=prompt,
tools=available_tools,
output_schema=expected_format
)
```
That’s it. No mention of Anthropic, OpenAI, Google, or anyone else.
Layer Two: The Gateway
The gateway sits between the agent and the model providers. It is responsible for:
- **Provider routing**: Deciding which model handles which request
- **Format translation**: Converting your internal request format to whatever the chosen provider expects, and translating the response back
- **Authentication**: Managing API keys for each provider
- **Retries and fallbacks**: If the primary provider fails, fall back to a secondary
- **Rate limiting**: Preventing runaway costs or API quota exhaustion
- **Logging and observability**: Recording every request and response with full metadata
- **Cost tracking**: Attributing spend to the right business unit or feature
Open-source tools like LiteLLM and Portkey implement this pattern out of the box. You can also build your own — a thin wrapper around the major providers’ SDKs is a few hundred lines of code. The build-vs-buy decision depends on how much customization you need.
The critical property is this: when you want to switch providers, **you change configuration in the gateway, not code in the agent**. The agent never knows the swap happened. That is the architectural prize.
The Hard Part: Behavioral Equivalence
The gateway makes the plumbing portable. It does not make the behavior portable. This is where most teams get into trouble.
When you swap from Model A to Model B, even with a perfect gateway, the responses will be different. The question is not whether they’ll differ — they will — but whether the differences matter for your use case. The only way to answer that question rigorously is with an **evaluation harness**.
This is non-negotiable for serious agent work. If you don’t have an eval harness, you don’t have a production AI system; you have a science experiment running in production.
What an Evaluation Harness Looks Like
An eval harness is a regression test suite for AI behavior. The components are:
**A representative test set.** Ideally 100 to 500 cases drawn from real production traffic, covering the range of inputs your agent actually encounters — the common cases, the edge cases, the failure modes you’ve already discovered. This set is curated, versioned, and grows over time as you find new edge cases in production.
**Defined success criteria for each case.** What does a correct response look like? Sometimes this is exact match (the agent must call this tool with these arguments). Sometimes it’s structural (the output must be valid JSON conforming to this schema). Sometimes it’s semantic (the response must convey these facts, regardless of wording). Sometimes it’s quality-graded by another model acting as a judge — “LLM-as-judge” — though this introduces its own evaluation problem.
**Automated execution.** You can run the entire test set against any candidate model with one command and get a comparative report. Task completion rate, tool-call accuracy, output format compliance, latency distribution, cost per request.
**Comparison against the incumbent.** The point isn’t just “does the new model pass” — it’s “does the new model regress versus what we have today.” A model that’s 95% correct on tests where the current model is 99% correct is a downgrade, even if 95% sounds good in isolation.
Tools like Promptfoo, DeepEval, LangSmith, and Braintrust are built specifically for this. Pick one and use it. The investment pays for itself the first time you avoid shipping a regression.
When You Run the Harness
You run it every time you consider any of the following:
- Swapping providers
- Upgrading to a new version of the same model
- Changing prompts in any meaningful way
- Adding or modifying tools
- Adjusting agent logic that affects what gets sent to the model
Treat it like a CI/CD pipeline for AI behavior. No change reaches production without passing eval. No exceptions, especially not “this is a small change.”
Operational Practices That Reinforce Portability
The architecture is necessary but not sufficient. A handful of operational practices make it actually work.
**Version-control your prompts separately from your code, and tag them with the model they were tuned for.** A prompt optimized for one model often needs adjustment to perform equivalently on another. Keep prompts in dedicated files — Markdown, YAML, whatever — with clear version history. When you port to a new model, you may need to fork the prompt for that model. That’s normal and expected.
**Force structured outputs wherever possible.** JSON schemas, function calls, and tool-use are far more portable across models than free-form prose. If your agent’s output format is rigorously specified, you reduce the surface area where models can drift in ways that break downstream systems. A model that produces JSON conforming to your schema is interchangeable in a way that a model producing prose paragraphs is not.
**Log every prompt and response in production, with the model version attached.** This serves two purposes. First, it gives you ground truth to evaluate against when you consider a swap — you can replay real production traffic against a candidate model and see what would have happened. Second, it gives you forensic capability when something goes wrong. “What did the agent say to that customer last Tuesday?” should always be answerable.
**Use canary deployments for model swaps.** Don’t flip 100% of traffic to the new model on day one. Route 5% to the candidate, compare real-world outcomes against the incumbent over a week or two, then ramp gradually. This catches the failure modes that don’t show up in your eval set because you didn’t think to test for them.
**Maintain a rollback path.** You should be able to revert to the previous model in minutes, not hours. Treat model versions like software releases — tagged, documented, redeployable on demand.
The Honest Accounting
Can this architecture eliminate the risk of model swaps breaking your agent? No.
What it can do is move the risk from “we find out in production from angry customers” to “we catch regressions in our eval suite before shipping.” The teams that do this well treat model swaps the way you’d treat swapping a database engine in a critical system — with a migration plan, a test suite, a canary rollout, and a rollback path. Not as a config change.
The cost is real. You’re investing in infrastructure — a gateway layer, an eval harness, prompt versioning discipline, observability — that doesn’t directly produce business value. It produces optionality, resilience, and the ability to evolve your AI stack without crisis. That’s not free, but the alternative — being permanently locked into whatever model you started with, or discovering breakage in production every time something changes — is far more expensive.
This is the same trade-off competent engineering organizations have always made. You don’t write production database code that assumes a specific vendor’s proprietary SQL extensions. You don’t hardcode credentials into application logic. You don’t deploy to production without tests. The principles are not new. AI agents just give us a new domain to apply them in.
The Bottom Line
Model portability isn’t a feature you bolt on later. It’s an architectural decision you make at the start, or pay dearly to retrofit.
The pattern is simple in concept: separate your agent logic from any specific model provider via a gateway, and verify behavioral equivalence with a rigorous evaluation harness before any swap. The execution requires discipline — prompt versioning, structured outputs, comprehensive logging, canary deployments, and a culture that treats AI changes with the same seriousness as any other production change.
Companies that build this foundation can move with the market. They can adopt better models when they appear, negotiate from a position of strength with providers, and absorb the inevitable changes in the AI landscape without their agents breaking. Companies that don’t build this foundation are betting that the model they picked at the start will remain optimal forever. That’s not a bet I’d take.
The good news is that this is a solved problem in pattern, even if every implementation is unique. The architecture is well-understood, the tools exist, and the practices are documented. What’s required is the will to do it right the first time.
That’s amplification architecture. The alternative is hope, and hope is not a strategy.

-----
*Marcus McEwen is the founder of Tech Wolves AI Advisory, providing AI implementation consulting to companies in the $5–20M revenue range. He previously founded and sold Equivoice, a managed service provider, and brings 36 years of technology experience including foundational systems analysis training from AT&T.*
-----
Appendix: Architectural Diagram Specifications
The following specifications can be used to generate diagrams in Mermaid, Excalidraw, draw.io, Lucidchart, or any architectural drawing tool. Each diagram is described in enough detail to be rendered directly.
Diagram 1: The Naive Architecture (What Most Companies Have)
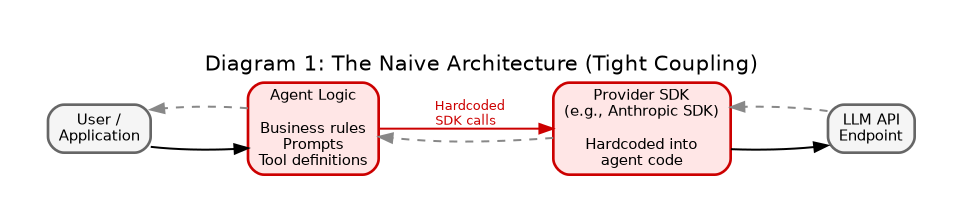
**Type:** Simple linear flow diagram
**Components:**
- User / Application (left)
- Agent Logic (center) — contains business logic, prompts, tool definitions
- Provider SDK (right) — hardcoded to a specific provider, e.g., Anthropic
- LLM API (far right) — the provider’s API endpoint
**Flow:** User → Agent Logic → Provider SDK → LLM API, with response flowing back
**Annotations:**
- Red highlight on the connection between Agent Logic and Provider SDK, labeled “TIGHT COUPLING — model provider is hardcoded into agent logic”
- Caption beneath: “Switching providers requires rewriting agent code”
**Mermaid version:**
```mermaid
flowchart LR
U[User / Application] --> A[Agent Logic<br/>Business rules<br/>Prompts<br/>Tool definitions]
A -->|Hardcoded SDK calls| P[Provider SDK<br/>e.g., Anthropic SDK]
P --> L[LLM API]
L --> P
P --> A
A --> U
style A fill:#ffe6e6
style P fill:#ffe6e6
```
Diagram 2: The Portable Architecture (Two-Layer Pattern)
**Type:** Layered architecture diagram
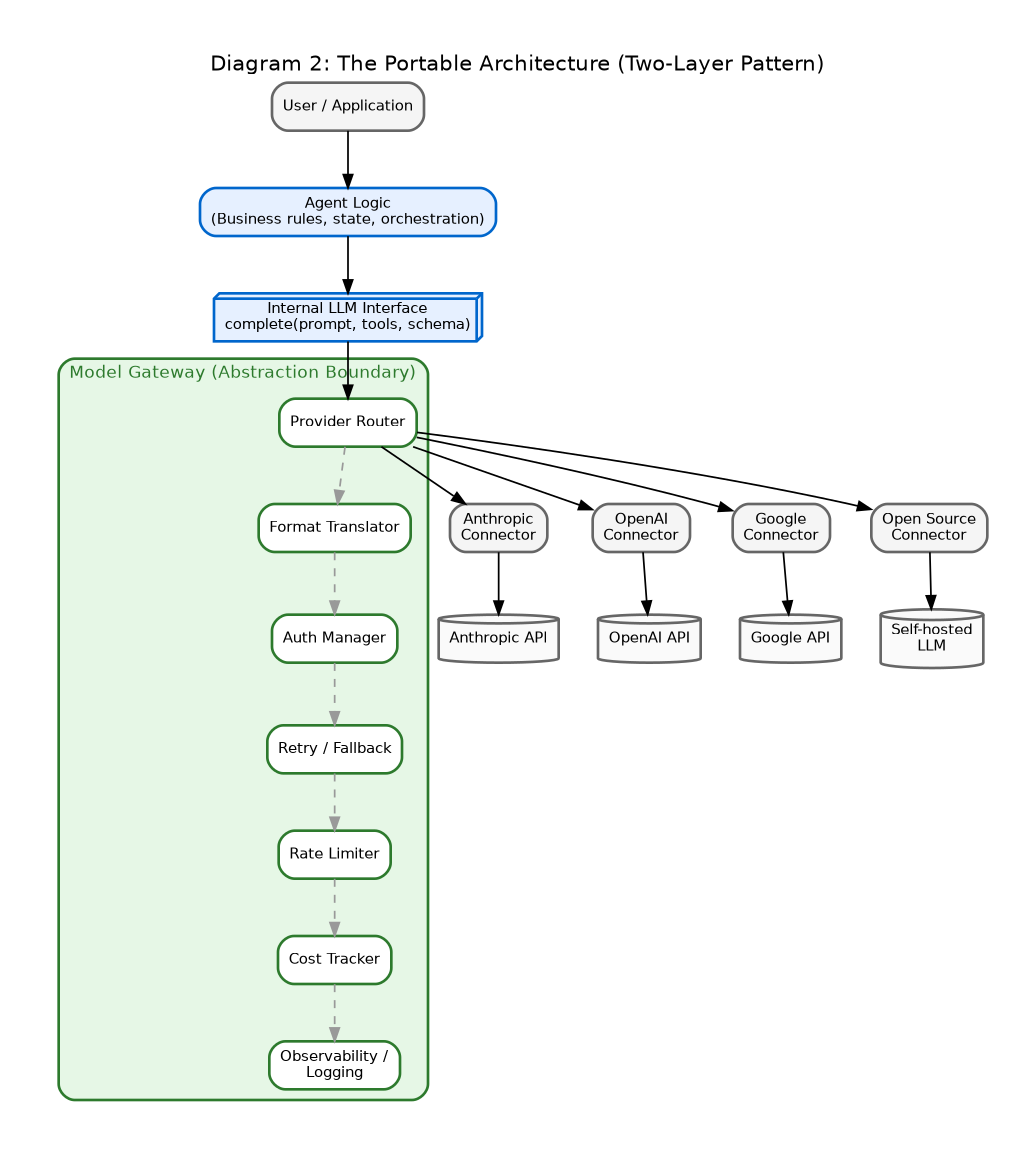
**Components organized in tiers from top to bottom:**
*Tier 1 — Application Layer:*
- User / Application
- Agent Logic (business rules, conversation state, tool orchestration)
*Tier 2 — Gateway Layer (the abstraction boundary):*
- Internal LLM Interface (a single function signature: `complete(prompt, tools, schema)`)
- Model Gateway with sub-components:
- Provider Router
- Format Translator
- Auth Manager
- Retry / Fallback Logic
- Rate Limiter
- Cost Tracker
- Observability / Logging
*Tier 3 — Provider Layer:*
- Multiple parallel provider connectors: Anthropic, OpenAI, Google, Open Source (e.g., self-hosted Llama)
**Flow:** Agent Logic calls the Internal LLM Interface, which routes through the Gateway components, which dispatches to the appropriate Provider Connector, which calls the actual API.
**Annotations:**
- Green highlight on the boundary between Agent Logic and Gateway, labeled “ABSTRACTION BOUNDARY — agent has zero knowledge of providers”
- Note on Provider Router: “Configuration-driven; swap providers without code changes”
- Note on Observability: “Every request logged with provider, model version, latency, cost, full prompt and response”
**Mermaid version:**
```mermaid
flowchart TB
U[User / Application] --> A[Agent Logic<br/>Business rules, state, orchestration]
A -->|complete prompt, tools, schema| I[Internal LLM Interface]
subgraph Gateway[Model Gateway]
I --> R[Provider Router]
R --> FT[Format Translator]
FT --> AM[Auth Manager]
AM --> RF[Retry / Fallback]
RF --> RL[Rate Limiter]
RL --> CT[Cost Tracker]
CT --> O[Observability / Logging]
end
O --> P1[Anthropic Connector]
O --> P2[OpenAI Connector]
O --> P3[Google Connector]
O --> P4[Open Source Connector]
P1 --> API1[Anthropic API]
P2 --> API2[OpenAI API]
P3 --> API3[Google API]
P4 --> API4[Self-hosted LLM]
style Gateway fill:#e6f7e6
style A fill:#e6f0ff
```
Diagram 3: The Evaluation Harness Workflow
**Type:** Process flow diagram showing the model swap lifecycle
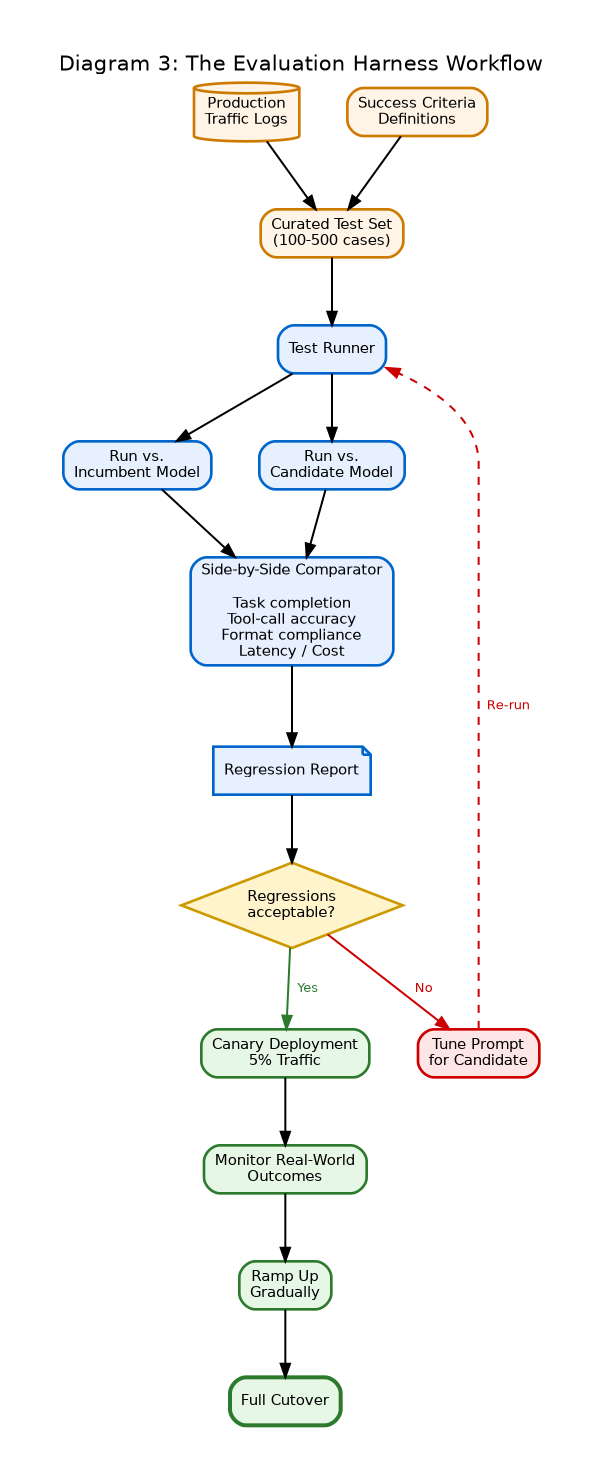
**Components:**
*Inputs (left):*
- Production Traffic Logs
- Curated Test Set (100–500 cases)
- Success Criteria Definitions
*Process (center):*
- Test Runner — executes each case against both incumbent and candidate model
- Side-by-Side Comparator — measures task completion, tool-call accuracy, format compliance, latency, cost
- Regression Report — pass/fail per case, aggregate metrics, deltas vs. incumbent
*Decision Point:*
- Diamond shape: “Regressions acceptable?”
- Yes branch → Canary Deployment (5% traffic) → Monitor → Ramp Up → Full Cutover
- No branch → Tune Prompt for Candidate Model → Re-run Eval (loop back)
*Outputs:*
- Production Cutover (right)
- OR Rejected Candidate (back to drawing board)
**Mermaid version:**
```mermaid
flowchart TB
PT[Production Traffic Logs] --> TS[Curated Test Set<br/>100–500 cases]
SC[Success Criteria] --> TS
TS --> TR[Test Runner]
TR --> M1[Run vs. Incumbent Model]
TR --> M2[Run vs. Candidate Model]
M1 --> CMP[Side-by-Side Comparator<br/>Task completion<br/>Tool-call accuracy<br/>Format compliance<br/>Latency / Cost]
M2 --> CMP
CMP --> RR[Regression Report]
RR --> D{Regressions<br/>acceptable?}
D -->|No| TP[Tune Prompt<br/>for Candidate]
TP --> TR
D -->|Yes| CD[Canary Deployment<br/>5% Traffic]
CD --> MON[Monitor Real-World<br/>Outcomes]
MON --> RU[Ramp Up Gradually]
RU --> FC[Full Cutover]
style D fill:#fff4cc
style CD fill:#e6f7e6
style FC fill:#e6f7e6
```
### Diagram 4: End-to-End Production View
**Type:** Combined system diagram showing all elements working together
**Components grouped into three swim lanes:**
*Top lane — Runtime Path:*
User → Agent → Gateway → Provider → Model → back through the chain
*Middle lane — Observability:*
Every request and response is captured and written to a Log Store. The Log Store feeds two downstream systems: a Production Dashboard (for monitoring health, cost, latency) and the Test Set Curation system (for harvesting new edge cases).
*Bottom lane — Change Management:*
Prompt Repository (version-controlled) feeds the Agent. Eval Harness pulls from both the Test Set Curation system and the Prompt Repository. Eval Harness output gates promotion to the Production Configuration that drives the Gateway’s provider routing.
**Annotations:**
- Arrow from Production Logs to Test Set Curation labeled “Real traffic continuously informs the eval set”
- Arrow from Eval Harness to Production Configuration labeled “No model or prompt change reaches production without passing eval”
**Mermaid version:**
```mermaid
flowchart TB
subgraph Runtime[Runtime Path]
U[User] --> AG[Agent]
AG --> GW[Gateway]
GW --> PR[Provider]
PR --> MD[Model]
end
subgraph Observability
GW --> LS[Log Store]
LS --> PD[Production Dashboard]
LS --> TC[Test Set Curation]
end
subgraph ChangeManagement[Change Management]
PRPT[Prompt Repository<br/>version-controlled] --> AG
TC --> EH[Eval Harness]
PRPT --> EH
EH --> PC[Production Configuration]
PC --> GW
end
style Runtime fill:#e6f0ff
style Observability fill:#fff4e6
style ChangeManagement fill:#e6f7e6
```
-----
*These diagrams can be rendered as-is in any Mermaid-compatible tool, or used as specifications for visual design in Excalidraw, Lucidchart, or Figma. For a polished version, the recommended approach is to render the Mermaid diagrams first to validate structure, then redraw in a visual tool with consistent typography and brand colors.*