
Sovereign Domain Information Architecture
GIGo still rules


The ability to effectively use AI begins and ends with the quality of your data and how you present it. The primary rule of information technology has not changed. Garbage in gets you garbage out. This is even more true with artificial intelligence, because AI scales whatever you give it — including your disorganization.
The Cisco Audit That Changed How I Think About Information
I founded, owned, and operated a managed service provider. We were initially very successful based on the skills of the founders. Each of us understood the other, and we achieved remarkable goals for a small company. But our information architecture was built on tribal knowledge — information scattered across silos, communication systems that worked for two highly motivated entrepreneurs but did not translate into a larger organization.
We wanted to earn Cisco master service provider status. The certification required passing an ITIL-based audit. ITIL — the Information Technology Infrastructure Library — is a framework for organizing how a service company manages its processes and documentation. At the start of the process, there was no way we would have passed.
So we rebuilt. We reorganized the company around ITIL processes, implemented clear policies and procedures, and passed the audit. My little company received the same certification as AT&T.
Here is what that experience taught me: if an outside auditor cannot understand your policies and procedures without you handholding them, neither will AI. The discipline that made us auditable is exactly the discipline that makes a business AI-ready. These are not different problems.
The Wall
After retiring from the IT business in 2017, I started Tech Wolves AI Advisory while continuing to manage an Airbnb in Atlanta. I began using AI across these activities and quickly ran into a familiar problem — my own information architecture was a mess. I had data spread across Google Drive, Microsoft OneDrive, email, QuickBooks, Excel, and an iPad file system. No consistent structure. No clear logic that anyone other than me could follow.
I asked Claude to research some items using my existing Google Drive as the source. It did not go well. Files were scattered, formats were incompatible, and the organization only made sense because I had built it. There was also a significant amount of personal information I had no interest in exposing through AI queries.
Building an AI-Ready Architecture
I decided to create a dedicated drive specifically for AI access. My approach was straightforward: if I was going to build a file structure that AI could navigate, I should use AI to help design it. Claude and I developed the structure together.
The next problem was migration. Claude can only access one drive at a time, which made moving selected files from the old drive to the new one difficult. I brought Gemini into the process because it can access multiple drives simultaneously. Gemini and I identified the relevant documents, staged them in a transfer folder, and Gemini generated a script that moved them to the new drive while converting incompatible formats — Word documents into Google Docs, for example — into a consistent format both Claude and Gemini could read.
The result is a curated database with a clean file structure and an index file that any AI model can locate and use to navigate the documentation. The structure is designed so that decision criteria, process documentation, and supporting information are all findable without me acting as a guide.
Appendix A details the architecture
Summary
Garbage in, garbage out still reigns. Exposing a poorly designed information architecture to AI will not produce optimal results — it may make things worse by amplifying your existing disorganization at scale.
Appendix A : Current Google Drive Structure
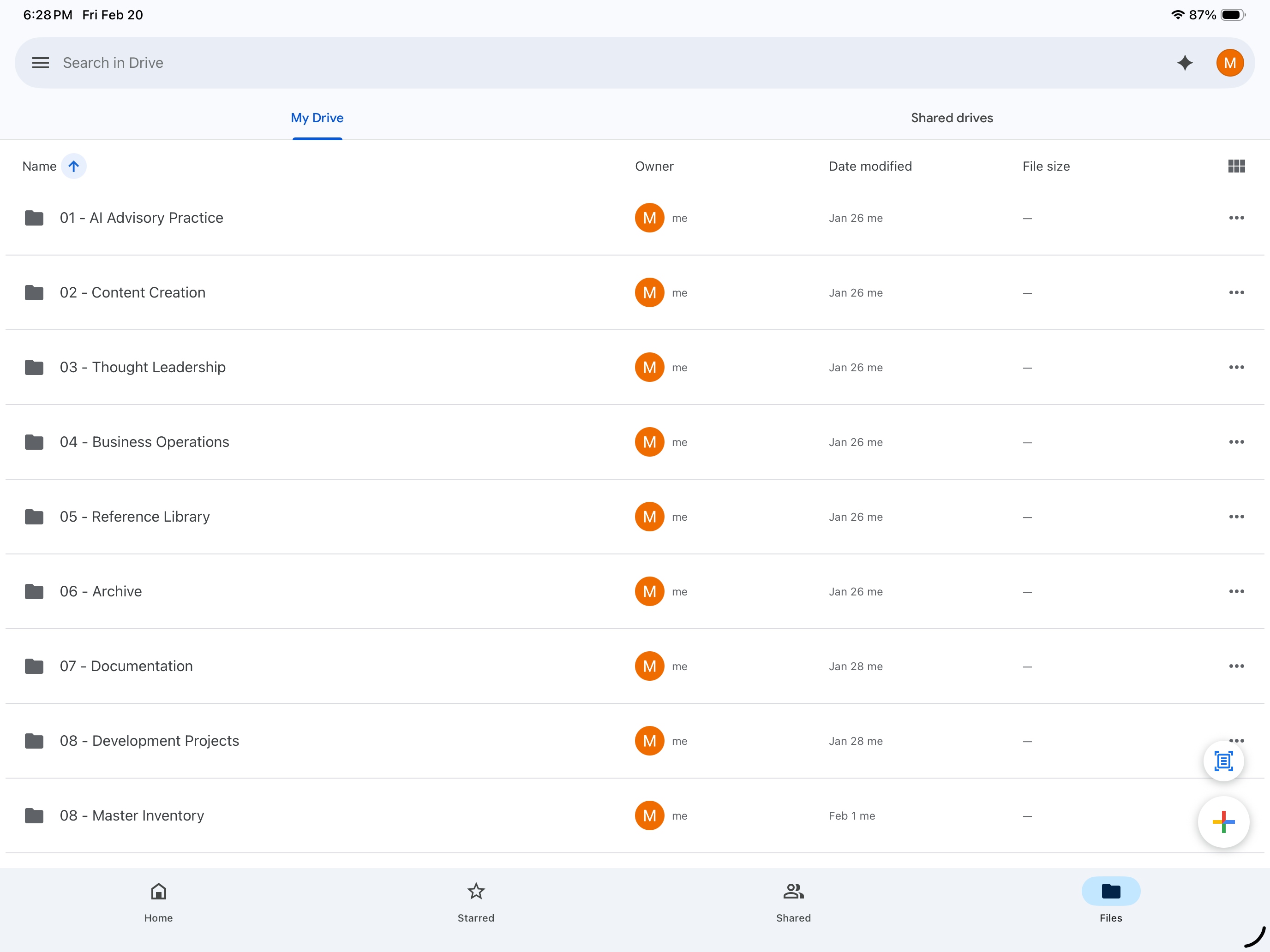
The following shows the top-level folder structure of the AI-dedicated Google Drive. Each folder is numbered to establish a consistent navigation logic that both human users and AI models can follow without additional guidance. The numbering is not arbitrary — it reflects the sequence in which information is likely to be needed, from active advisory work through to archived and development materials.
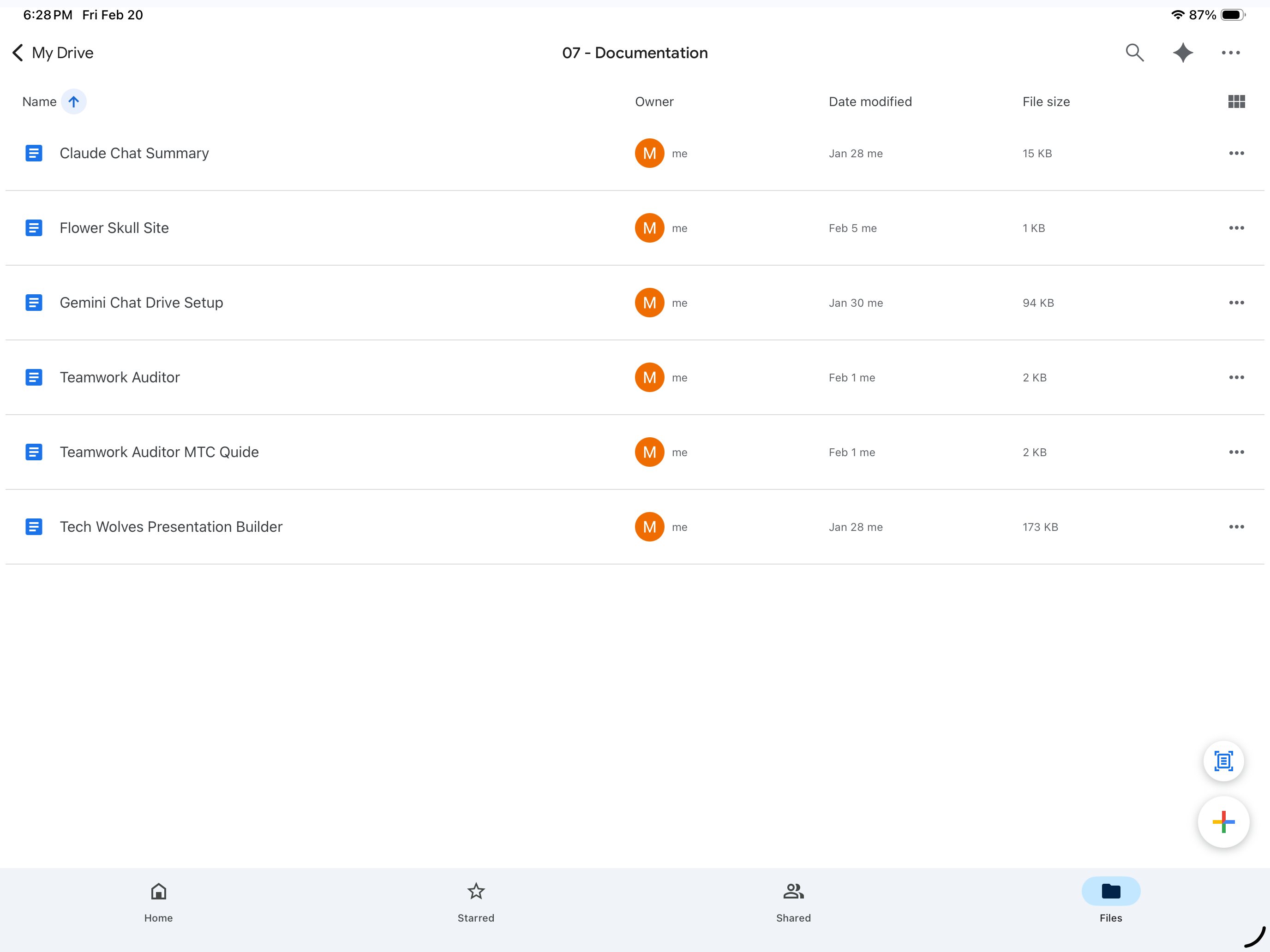
To illustrate how the structure works in practice, the following shows the contents of folder 07 - Documentation. This folder contains the working records of how the AI tools and processes in this drive were built — including chat summaries from Claude and Gemini sessions, tool documentation, and process guides. This is the kind of institutional memory that typically lives in someone’s head. Here it is findable, readable, and accessible to any AI model working within this drive.
The structure will evolve as the practice grows. The index file at the root level ensures that any AI model entering this drive can orient itself without a guided tour.