
Domain Specific LLM
A method to overcome the limitations of public large language models.

Intended Audience
This blog is primarily written for people who are not data scientists or artificial intelligence engineers. Is written for business owners and key management personnel who would like to be familiar with AI so they can intelligently discuss their options with technical personnel. As a result of reading this blog, you should have a good general idea of how domain specific large language models work and how you might use them in your company. This will give you a much better perspective on how to manage the process and identify the benefits to your organization
Introduction
Large language models are very helpful. I use them all the time. They are great for research, art, programming, and all kinds of other important tasks. We are entering the age of of Agentic AI. They promise that AI agents will be able to improve productivity and increase profits. However, I would never deploy a mission critical application that needed consistent performance on a public large language model.
For example, I used to own and operate a managed service provider. There is no way that I would put any of my network support functions on a public large language model. I might use them to help configure a router or research an application, but I would never rely on it for anything that would affect our service level agreements. There are too many variables out of my control, and I have trained none of the public LLM’s on my specific data or needs. I know there are methods such as RAG that can help you receive better results from a public large language model, but they are still subject to the status of the public large language model.
This does not mean that I would not use large language models or artificial intelligence in my organization. I would continue to use the public large language models when it was appropriate. However, I would create a domain specific large language model that my organization managed.
As a side note, following the main part of this blog, there are a series appendices going to much greater detail on domain specific large language, models and how they operate in what is required to implement one.
Public LLM Limitations
I asked Claude 4.0 sonnet to provide me a list of the limitations of public large language models. I reviewed Claude‘s response and decided that it did not need any revisions. The following is Claude‘s list of public LLM limitations.
Depth vs. Breadth Trade-off
My training covers an enormous range of topics, but this breadth comes at the cost of specialized depth. While I can discuss medical concepts, I lack the nuanced understanding that comes from training exclusively on medical literature, clinical data, and specialized terminology that a medical-specific model would have.
Limited Domain-Specific Reasoning
I may miss subtle domain-specific relationships and reasoning patterns that experts take for granted. For example, in legal contexts, I might not fully grasp the implications of specific case law precedents or understand how different jurisdictions’ laws interact in complex ways.
Terminology and Jargon Gaps
While I know many specialized terms, I may not understand the full contextual meaning or latest usage patterns within specific fields. Domain-specific models trained on current industry publications would have more precise and up-to-date terminology understanding.
Task-Specific Optimization
My responses are optimized for general conversation and broad helpfulness, not for specific professional workflows. A financial model might be better at parsing SEC filings or a coding model more efficient at generating production-ready code with proper error handling.
Knowledge Currency in Specialized Fields
Fast-moving domains like medicine, technology, or regulatory compliance require extremely current information. My knowledge cutoff means I may miss recent developments that could be critical for professional applications.
Risk and Accuracy Requirements
In high-stakes domains like healthcare or legal advice, the margin for error is much smaller than in general conversation. Domain-specific models can be trained with stricter accuracy requirements and specialized evaluation metrics.
Contextual Understanding
I might not fully appreciate the real-world constraints, workflows, and decision-making processes specific to particular industries, leading to suggestions that are theoretically sound but practically problematic.
These limitations make specialized models valuable for professional applications where precision, currency, and deep domain expertise are critical.
For example, in my use case, there were specific policies and procedures that needed to be followed and enforced. These policies and procedures r required access to corporate data. This data came from policy manuals, network management systems, accounting, CRM and variety of other sources. In addition, the data was constantly changing. Network management systems, ticket systems, accounting systems were all constantly updating databases.
Fortunately, there are privately managed domain specific large language models that you can specifically train on your data and structure it to meet your needs.
Domain Specific Large Language Models
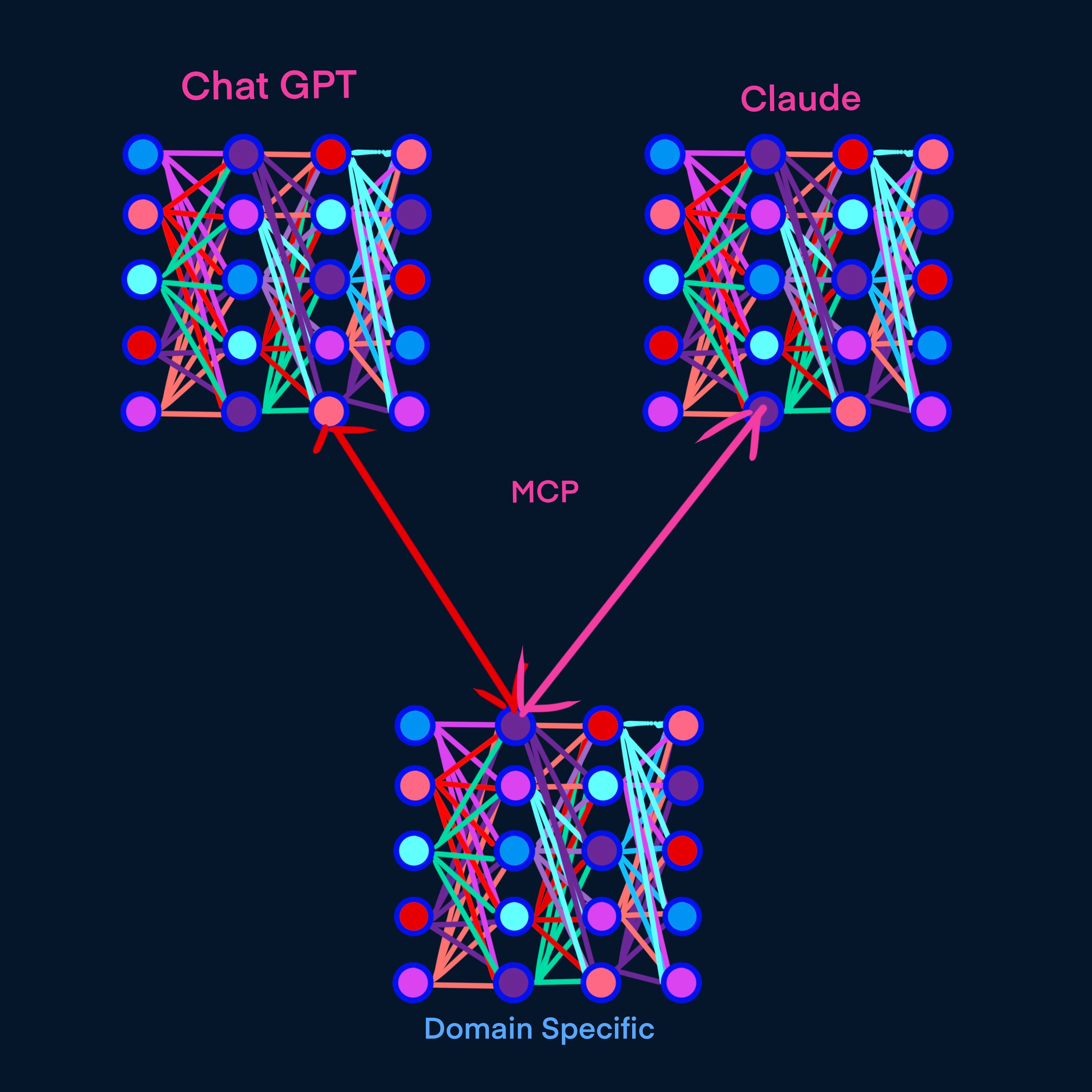
Once again, I will have Claude provide the definition of a domain specific large language model
A domain-specific large language model is a language model that has been specifically trained, fine-tuned, or adapted to excel at tasks within a particular field, industry, or area of knowledge, rather than being designed for general-purpose use.
These models typically start with a foundation model (like GPT, BERT, or similar architectures) and then undergo additional training on specialized datasets from the target domain. This process helps them develop deeper understanding of domain-specific terminology, concepts, reasoning patterns, and task requirements.
Key characteristics include:
Specialized training data: The model is exposed to large amounts of text and examples from the specific domain, such as medical literature for healthcare models, legal documents for legal AI, or scientific papers for research applications.
Enhanced domain knowledge: They demonstrate superior performance on domain-specific tasks compared to general models, understanding nuanced terminology, field-specific relationships, and specialized reasoning.
Targeted applications: These models are optimized for particular use cases like medical diagnosis assistance, legal document analysis, financial risk assessment, or scientific research support.
Various businesses and industries have already created domain specific large language models. The following link describes some of these models:
https://opendatascience.com/6-examples-of-doman-specific-large-language-models/
However, the devil is in the details and the systems are not simple to implement and manage.
Domain Specific Infrastructure Requirements
There are three basic models for developing a privately managed domain specific large language model. The first model involves you buying equipment and hosting it in your data network infrastructure, the second model is a cloud-based infrastructure, and the third model is a hybrid of the first two models.
The first model offers the most control while requiring a large capital investment and an in-house staff of data scientists and AI support engineers. The second model reduces capital equipment investment and reduces the requirement for infrastructure support; however, you must deal with all the problems of using a public cloud. The third model enables you to achieve the benefits of the first two models while mitigating some of the cost and risks. Whatever model you choose, you will need the following basic components. Gemini developed this list.
Core Hardware Components: The Building Blocks of Your LLM
At the heart of any LLM implementation is a powerful set of hardware components designed to handle the immense computational demands of training and running these complex models.
Graphics Processing Units (GPUs) are the most critical element. Their parallel processing capabilities are essential for the matrix operations that form the backbone of neural networks. For training or fine-tuning a domain-specific LLM, high-end, data-center-grade GPUs with large amounts of video RAM (VRAM) are paramount. Look for models like NVIDIA's A100 or H100 series, which are specifically designed for AI workloads. The amount of VRAM will directly impact the size of the model and the batch size of data you can process at once. For inference, the GPU requirements might be slightly less demanding, but a powerful GPU is still necessary for low-latency responses.
A powerful Central Processing Unit (CPU) is also crucial. While the heavy lifting of model training is done by the GPUs, the CPU handles data preprocessing, loading, and orchestrating the overall workflow. High-core-count processors like AMD's Threadripper Pro or Intel's Xeon series are recommended to prevent bottlenecks and ensure a smooth data pipeline to the GPUs.
Sufficient Random Access Memory (RAM) is another key consideration. A general rule of thumb is to have at least twice the amount of system RAM as the total VRAM of your GPUs. For training large models, 256GB of RAM or more is a common starting point. This ensures that the CPU can efficiently manage and feed data to the GPUs.
Finally, fast storage is non-negotiable. NVMe Solid State Drives (SSDs) are essential for quickly loading and accessing the massive datasets required for training and for storing model checkpoints. The storage capacity will depend on the size of your datasets and the number of models you plan to manage, but several terabytes of fast storage is a typical requirement.
In addition, you will need access to engineering and operational support resources. Gemini provides the following lists of resources:
1. Data and Domain Expertise Team 🧠
This team is responsible for sourcing, cleaning, and managing the most critical component: your proprietary data. For a domain-specific model, their work is the foundation of its success.
• Data Engineers: These are the architects of your data pipeline. They build and maintain the systems that extract, transform, and load (ETL) your domain-specific data from various sources into a centralized data lake or warehouse. They ensure data is clean, organized, and ready for the AI team.
• Subject Matter Experts (SMEs): Often overlooked, SMEs are your internal experts in the specific domain (e.g., legal, medical, finance, engineering). They are not necessarily technical but are crucial for annotating data, validating the model's responses, and ensuring the LLM's outputs are accurate and contextually relevant.
• Data Governance & Compliance Specialists: This role is vital for a privately managed system. They ensure that the data used for training complies with privacy regulations (like GDPR or HIPAA) and internal data handling policies, mitigating legal and ethical risks.
2. Core AI and Modeling Team 🔬
This is the team that builds, trains, and refines the LLM itself. They are the core researchers and developers of the AI.
• Machine Learning (ML) Scientists / Research Scientists: This is a more specialized version of a "Data Scientist." They focus on the theoretical aspects of the model. They select the right base model architecture, design the fine-tuning strategy, conduct experiments, and push the boundaries of the model's performance. They live and breathe research papers and transformer architectures.
• ML Engineers (MLOps): These engineers are the bridge between the experimental models created by scientists and a production-ready system. They build the infrastructure for reproducible training runs, manage model versioning, automate the deployment process, and monitor the model's performance in production. They are experts in tools like Kubernetes, MLflow, and cloud AI platforms.
3. Infrastructure and Hardware Team ⚙️
This team, which includes your network engineers, builds and maintains the high-performance computing environment the LLM needs to live in.
• Infrastructure/Cloud Engineers: They are responsible for setting up and managing the core compute, storage, and GPU resources. Whether on-premises or in a private cloud, they handle the servers, virtualization, and operating systems.
• Networking Engineers: As you mentioned, this is a critical role. For distributed training across many GPUs, they design and manage high-bandwidth, low-latency networks (using technologies like InfiniBand or RoCE) to ensure data can flow between nodes without bottlenecks. A slow network can bring a multi-million dollar GPU cluster to its knees.
• Security Engineers (SecOps): They focus on securing the entire infrastructure, from the network perimeter to the data at rest. They manage access controls, monitor for threats, and ensure the proprietary model and data are protected from unauthorized access.
4. Application and Product Team 🚀
This team is responsible for making the LLM usable and integrating it into actual business applications.
• Backend Engineers: They build the APIs that expose the LLM's capabilities to other software. They handle user authentication, manage inference requests, and ensure the service is scalable and reliable.
• Frontend / Full-Stack Developers: They build the user-facing applications that interact with the LLM, such as internal chatbots, search tools, or data analysis dashboards.
• UI/UX Designers: They design the user experience, ensuring that interacting with the powerful LLM is intuitive, efficient, and useful for employees or customers.
• Quality Assurance (QA) Engineers: They are responsible for testing the entire system, from the API endpoints to the user interface, and importantly, for testing the quality and consistency of the LLM's responses.
5. Leadership and Governance 🧭
This group provides strategic direction and oversight for the entire project.
• Product/Project Manager: This person owns the LLM initiative from a business perspective. They define the use case, manage the roadmap, prioritize features, and act as the liaison between the technical teams and business stakeholders.
• Head of AI / ML Lead: This is the senior technical leader responsible for the overall AI strategy and architecture. They guide the modeling team, make key technical decisions, and ensure the project stays on track and adopts best practices
This is a daunting list of technical resources to recruit, train and manage. Most small and businesses do not have the resources to handle this kind of project. The ongoing expenses of maintaining this kind of staff would overwhelm the benefits. However, if they do not implement AI agents they might find themselves at a competitive disadvantage against larger companies who do have the resources.
Outsourcing Implementation and Operational Management

Outsourcing offers small and medium businesses the ability to implement a domain specific large language model without having to add these elevated levels of expertise to their staff. This is also an excellent business opportunity for consulting companies and service providers.
There is one component to domain specific LLM implementation that cannot be outsourced. You can receive consulting advice, but in the end, you have to be responsible for your data. The quality and quantity of your data is the most important element of your LLM strategy. If you have conflicting, out of date and low quality data, it is a waste of time to implement a domain specific large language model. The most important rule of IT has never changed. Garbage in equals garbage out.
It is important that you spend time preparing your data. You are the subject matter experts on how your organization runs. There are consultants who can help you, but in the end, you know more about it than anyone. I cannot emphasize how important it is to concentrate on this aspect of LLM management.
Here are some of the other considerations that you need to address. These were compiled by Gemini.
How the Outsourced Model Works
In this arrangement, you would partner with a third-party service provider, which could be a global systems integrator, a specialized AI consultancy, or a managed service provider (MSP).
The Service Provider's Responsibilities:
• Infrastructure Management: They design, deploy, and manage the entire hardware and cloud infrastructure stack. This includes provisioning the GPUs, managing the high-speed networking, and ensuring the compute environment is stable and optimized.
• MLOps (Machine Learning Operations): They handle the entire technical lifecycle of the LLM. This includes setting up the data pipelines, running the fine-tuning process, versioning the models, deploying the model for inference via a secure API, and monitoring its performance, uptime, and cost.
• Technical Troubleshooting & Maintenance: They are on the hook for keeping the system running. If a GPU server fails or the API goes down, it's their job to fix it.
• Staying Current: They are responsible for staying up-to-date with the rapidly evolving AI landscape and advising on when to upgrade the model architecture or infrastructure.
Your Company's Responsibilities:
• Subject Matter Expertise (SME): Your internal experts are the key to success. They provide, curate, and label the domain-specific data. They are also critical for evaluating the model's output through techniques like Reinforcement Learning with Human Feedback (RLHF), ensuring its responses are accurate, relevant, and safe for your business context.
• Strategic Direction & Product Management: Your team defines the goals. What business problem is the LLM solving? Who are the end-users? What are the key performance indicators (KPIs) for success? The vendor builds what you tell them to build.
• Data Governance & Provisioning: You are the steward of your data. Your team is responsible for providing the service provider with secure access to the necessary data and ensuring that this process complies with all internal and external regulations.
• Vendor & Contract Management: You need a strong internal project lead to manage the relationship with the service provider, ensuring they meet deadlines, stay on budget, and deliver on their promises.
Summary
There is massive hype about the productivity and usefulness of AI agents. However, the road from hype to reality is long and twisted. Public large language models are too inconsistent and two general for Mission critical applications. They do not allow you to find tune AI to meet your specific needs, and there are security and other issues associated with using a large language model.
A domain specific large language model overcomes many of the obstacles associated with a public large language model. They enable you to input your specific data and requirements while fine-tuning it to meet the needs of your company. This does require a large commitment of capital and human resources.
It is complicated and requires a very detailed implementation plan. Fortunately, there are multiple methods of implementing a domain specific large language model. There are also external resources to help with your implementation. With the right plan in combination with an understanding of your needs, a domain specific large language model ca be the key to unlocking the benefits of artificial intelligence and AI agents for your organization.
There are a series of AI generated planning documents, following the summary that you can refer to for more detail
Appendices
The following are a series of queries in their responses from public large language models on the subject of domain specific large language models
What hardware and infrastructure components would be required to implement a domain specific LL M in a private organization?
Building Your Own AI Powerhouse: The Hardware and Infrastructure for a Private, Domain-Specific LLM
Implementing a domain-specific Large Language Model (LLM) within a private organization is a significant undertaking that requires a robust and carefully planned hardware and infrastructure foundation. This investment empowers an organization to maintain control over its data, tailor the model to its specific needs, and potentially achieve a competitive advantage. The necessary components can be broken down into three key stages: data preparation, model training or fine-tuning, and inference. The choice of an on-premises, cloud, or hybrid infrastructure model will further influence the specific requirements.
Core Hardware Components: The Building Blocks of Your LLM
At the heart of any LLM implementation is a powerful set of hardware components designed to handle the immense computational demands of training and running these complex models.
Graphics Processing Units (GPUs) are the most critical element. Their parallel processing capabilities are essential for the matrix operations that form the backbone of neural networks. For training or fine-tuning a domain-specific LLM, high-end, data-center-grade GPUs with large amounts of video RAM (VRAM) are paramount. Look for models like NVIDIA's A100 or H100 series, which are specifically designed for AI workloads. The amount of VRAM will directly impact the size of the model and the batch size of data you can process at once. For inference, the GPU requirements might be slightly less demanding, but a powerful GPU is still necessary for low-latency responses.
A powerful Central Processing Unit (CPU) is also crucial. While the heavy lifting of model training is done by the GPUs, the CPU handles data preprocessing, loading, and orchestrating the overall workflow. High-core-count processors like AMD's Threadripper Pro or Intel's Xeon series are recommended to prevent bottlenecks and ensure a smooth data pipeline to the GPUs.
Sufficient Random Access Memory (RAM) is another key consideration. A general rule of thumb is to have at least twice the amount of system RAM as the total VRAM of your GPUs. For training large models, 256GB of RAM or more is a common starting point. This ensures that the CPU can efficiently manage and feed data to the GPUs.
Finally, fast storage is non-negotiable. NVMe Solid State Drives (SSDs) are essential for quickly loading and accessing the massive datasets required for training and for storing model checkpoints. The storage capacity will depend on the size of your datasets and the number of models you plan to manage, but several terabytes of fast storage is a typical requirement.
Infrastructure Models: Where Your LLM Will Live
The choice of where to house your hardware and run your LLM operations is a strategic decision with significant implications for cost, scalability, and control.
• On-Premises Infrastructure: This model offers the highest level of control over data and security. All hardware is owned and managed by the organization within its own data centers. This is often the preferred choice for organizations in highly regulated industries or those with extremely sensitive data. However, it requires a significant upfront investment in hardware, as well as the expertise to manage and maintain the infrastructure.
• Cloud Infrastructure: Utilizing a major cloud provider like Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure offers flexibility and scalability. These providers offer on-demand access to powerful GPUs and other necessary hardware, eliminating the need for large capital expenditures. This model is ideal for organizations that want to experiment with different model sizes and configurations without a long-term hardware commitment. The downside is the potential for high operational costs, especially during intensive training periods, and potential data privacy concerns for some organizations.
• Hybrid Infrastructure: This approach combines the benefits of both on-premises and cloud solutions. An organization might choose to keep its sensitive data and core training infrastructure on-premises while leveraging the cloud for bursting capacity for large-scale training runs or for deploying less sensitive applications. This model offers a balance of control and flexibility but requires careful management and integration between the two environments.
Essential Infrastructure Components and Tools
Beyond the core hardware, a successful private LLM implementation relies on a sophisticated ecosystem of supporting infrastructure and software.
Networking: For distributed training, where a model is trained across multiple servers and GPUs, high-speed, low-latency networking is critical. Technologies like InfiniBand or high-speed Ethernet (100Gbps or more) are necessary to ensure efficient communication between nodes and prevent the network from becoming a bottleneck.
Data Management and Storage: A robust data pipeline is the foundation of a successful domain-specific LLM. This includes:
• Data Storage: Scalable storage solutions like network-attached storage (NAS) or object storage are needed to house large datasets.
• Data Lakes and Warehouses: These centralized repositories can help in organizing and managing the vast amounts of structured and unstructured data required for training.
• Data Processing and ETL (Extract, Transform, Load) Tools: Tools like Apache Spark are essential for cleaning, preprocessing, and transforming raw data into a format suitable for training.
MLOps (Machine Learning Operations) Platform: Managing the lifecycle of a domain-specific LLM requires a dedicated MLOps platform. This includes tools for:
• Experiment Tracking: Tools like Weights & Biases or MLflow are used to log and compare different training runs.
• Model Versioning: The ability to track and manage different versions of your model is crucial for reproducibility and governance.
• Continuous Integration/Continuous Deployment (CI/CD): Automating the process of testing and deploying new model versions.
• Model Monitoring: Continuously monitoring the performance of the deployed model in production to detect drift and ensure accuracy.
Security and Governance: For a private LLM, security and data governance are paramount. This involves:
• Access Control: Implementing strict access controls to the data and the model.
• Data Encryption: Encrypting data both at rest and in transit.
• Compliance: Ensuring that the entire infrastructure and all processes comply with relevant industry regulations (e.g., GDPR, HIPAA).
• Model Governance: Establishing clear policies for how the model is used and who is responsible for its outputs.
By carefully considering these hardware and infrastructure components, a private organization can build a powerful and secure platform to develop and deploy a domain-specific LLM that is tailored to its unique needs and drives significant business value.
Would it be possible to implement a domain specific LLM in a public cloud environment, such as AWS/
Yes, it's absolutely possible to implement a domain-specific Large Language Model (LLM) in a public cloud environment like Amazon Web Services (AWS). In fact, public clouds are a very common and often preferred way to build, train, and deploy these models.
Cloud providers like AWS offer a comprehensive suite of services that streamline the entire LLM lifecycle, from data preparation and model training to deployment and management. These platforms provide the necessary flexibility and scalability, which can be particularly advantageous when dealing with the demanding computational requirements of LLMs.
Key AWS Services for Building a Domain-Specific LLM
AWS offers a rich ecosystem of tools specifically designed for machine learning and AI workloads. Here are some of the core services you would use:
• Amazon SageMaker: This is a fully managed service that provides the tools to build, train, and deploy machine learning models at scale. For LLMs, SageMaker offers features like distributed training libraries that can significantly speed up the training process across multiple GPUs. It also simplifies the process of fine-tuning pre-trained models with your own domain-specific data.
• Amazon Bedrock: This service provides access to a range of high-performing foundation models from leading AI companies, including AI21 Labs, Anthropic, and Cohere, as well as Amazon's own Titan models. You can privately customize these foundation models with your own data, making it a powerful option for creating a domain-specific LLM without having to build a model from scratch.
• Compute and Storage Services:
• Amazon EC2 (Elastic Compute Cloud): You can provision powerful virtual servers with high-performance GPUs (like the P4d and P5 instances) that are essential for training and hosting LLMs.
• Amazon S3 (Simple Storage Service): This provides scalable and durable object storage for your large datasets and model artifacts.
• Networking and Security:
• Amazon VPC (Virtual Private Cloud): This allows you to create an isolated section of the AWS cloud where you can launch your resources in a virtual network that you define. This is crucial for securing your data and your LLM.
• AWS Identity and Access Management (IAM): This service enables you to manage access to AWS services and resources securely.
Security and Data Privacy Considerations
A primary concern when using a public cloud for a domain-specific LLM is the security and privacy of your proprietary data. AWS provides robust security features to address these concerns:
• Data Encryption: You can encrypt your data both at rest (in S3 and other storage services) and in transit (as it moves between services).
• Private Networking: By using a VPC, you can ensure that your training and inference endpoints are not exposed to the public internet.
• Compliance Certifications: AWS complies with a wide range of security standards and regulations, which can be beneficial for organizations in regulated industries.
By leveraging these security controls, you can build a secure environment for your domain-specific LLM that is isolated from other AWS customers.
Benefits and Challenges of Using the Public Cloud
Benefits:
• Scalability: You can easily scale your compute resources up or down as your needs change, paying only for what you use.
• Access to Cutting-Edge Hardware: Cloud providers offer access to the latest and most powerful GPUs without the need for a large upfront investment in hardware.
• Managed Services: Services like Amazon SageMaker and Bedrock handle much of the underlying infrastructure management, allowing your team to focus on building and refining your LLM.
• Faster Time to Market: The pre-built tools and services available in the cloud can significantly accelerate the development and deployment of your LLM.
Challenges:
• Cost Management: While the pay-as-you-go model is flexible, the costs of training and running a large-scale LLM can add up quickly. Careful cost management and optimization are essential.
• Data Governance: While AWS provides the tools for security, your organization is still responsible for implementing and managing a robust data governance framework.
• Vendor Lock-in: Building your LLM on a specific cloud provider's services can make it more difficult to migrate to a different provider in the future.
What type of human resource support would you need to Implement a privately managed domain specific LLM? This would include networking engineers as well as the data scientist to do the training.
Of course. Implementing a privately managed, domain-specific LLM requires a highly skilled, multi-disciplinary team that extends well beyond just data scientists and network engineers. It's a significant undertaking that blends expertise from data infrastructure, machine learning, software development, and project governance.
Here’s a breakdown of the human resource support you would need, categorized by their primary function in the LLM lifecycle.
1. Data and Domain Expertise Team 🧠
This team is responsible for sourcing, cleaning, and managing the most critical component: your proprietary data. For a domain-specific model, their work is the foundation of its success.
• Data Engineers: These are the architects of your data pipeline. They build and maintain the systems that extract, transform, and load (ETL) your domain-specific data from various sources into a centralized data lake or warehouse. They ensure data is clean, organized, and ready for the AI team.
• Subject Matter Experts (SMEs): Often overlooked, SMEs are your internal experts in the specific domain (e.g., legal, medical, finance, engineering). They are not necessarily technical but are crucial for annotating data, validating the model's responses, and ensuring the LLM's outputs are accurate and contextually relevant.
• Data Governance & Compliance Specialists: This role is vital for a privately managed system. They ensure that the data used for training complies with privacy regulations (like GDPR or HIPAA) and internal data handling policies, mitigating legal and ethical risks.
2. Core AI and Modeling Team 🔬
This is the team that builds, trains, and refines the LLM itself. They are the core researchers and developers of the AI.
• Machine Learning (ML) Scientists / Research Scientists: This is a more specialized version of a "Data Scientist." They focus on the theoretical aspects of the model. They select the right base model architecture, design the fine-tuning strategy, conduct experiments, and push the boundaries of the model's performance. They live and breathe research papers and transformer architectures.
• ML Engineers (MLOps): These engineers are the bridge between the experimental models created by scientists and a production-ready system. They build the infrastructure for reproducible training runs, manage model versioning, automate the deployment process, and monitor the model's performance in production. They are experts in tools like Kubernetes, MLflow, and cloud AI platforms.
3. Infrastructure and Hardware Team ⚙️
This team, which includes your network engineers, builds and maintains the high-performance computing environment the LLM needs to live in.
• Infrastructure/Cloud Engineers: They are responsible for setting up and managing the core compute, storage, and GPU resources. Whether on-premises or in a private cloud, they handle the servers, virtualization, and operating systems.
• Networking Engineers: As you mentioned, this is a critical role. For distributed training across many GPUs, they design and manage high-bandwidth, low-latency networks (using technologies like InfiniBand or RoCE) to ensure data can flow between nodes without bottlenecks. A slow network can bring a multi-million dollar GPU cluster to its knees.
• Security Engineers (SecOps): They focus on securing the entire infrastructure, from the network perimeter to the data at rest. They manage access controls, monitor for threats, and ensure the proprietary model and data are protected from unauthorized access.
4. Application and Product Team 🚀
This team is responsible for making the LLM usable and integrating it into actual business applications.
• Backend Engineers: They build the APIs that expose the LLM's capabilities to other software. They handle user authentication, manage inference requests, and ensure the service is scalable and reliable.
• Frontend / Full-Stack Developers: They build the user-facing applications that interact with the LLM, such as internal chatbots, search tools, or data analysis dashboards.
• UI/UX Designers: They design the user experience, ensuring that interacting with the powerful LLM is intuitive, efficient, and useful for employees or customers.
• Quality Assurance (QA) Engineers: They are responsible for testing the entire system, from the API endpoints to the user interface, and importantly, for testing the quality and consistency of the LLM's responses.
5. Leadership and Governance 🧭
This group provides strategic direction and oversight for the entire project.
• Product/Project Manager: This person owns the LLM initiative from a business perspective. They define the use case, manage the roadmap, prioritize features, and act as the liaison between the technical teams and business stakeholders.
• Head of AI / ML Lead: This is the senior technical leader responsible for the overall AI strategy and architecture. They guide the modeling team, make key technical decisions, and ensure the project stays on track and adopts best practices.
In short, building a private LLM is like building a complete, specialized software company within your organization. It requires a significant and sustained investment in a diverse range of highly skilled technical talent.