
AI vs Traditional Computing


Artificial intelligence does not function like a traditional computer. There is no traditional operating system that controls applications. It does not store data on a hard drive in a file system with specific locations. It is none of those things. It is a silicon brain. The purpose of this blog is to spark your awareness of the differences between the two architectures and adjust your expectations accordingly.
Neuromorphic Engineering
Artificial intelligence infrastructure is designed to mimic the human brain. Neuromorphic engineering is the process used to create the silicon brain. I will let Claude 3.0, a large language model, define neuromorphic engineering
“Neuromorphic engineering or neuromorphic computing is the term for designing and engineering computing systems that mimic the structure and function of biological neural networks found in the human brain. This approach involves creating artificial neural systems that operate using principles similar to how neurons and synapses work in biological brains, often employing specialized hardware architectures that can process information in a parallel, distributed manner like our brains do. “
This means you have to look at this differently than a traditional server, laptop, or a smart phone. I believe the most critical concept is to understand that it is trained, not programmed. This rearranges the entire development process.

Training vs Programming
We have all gone through the joy of setting up a new laptop or iPad. They generally come with a preloaded operating system and a series of pre loaded programs. When you start it up, the laptop will explicitly follow the direction of the software. Then you have to go through the initialization and set up process.
Large language models are not like that. You do not load a program into a large language model. You prompt it. This process is called prompt engineering. This is a very simplified explanation of a detailed topic. I will write more upon this letter.
It is important to understand that large language models store information in patterns. These patterns exist within a neural network. Claude 3.5 gives the following explanation of a neural network:
A physical neural network (artificial neural network in hardware) typically consists of:
1. Processing Units (artificial neurons) - These can be implemented using:
- Transistors
- Integrated circuits
- Specialized neuromorphic chips
2. Connection Elements (artificial synapses) - Physical components that connect neurons:
- Resistors
- Capacitors
- Memristors (specialized components that can "remember" previous states)
3. Input/Output Interfaces:
- Input sensors or data ports
- Output interfaces
- Signal conversion components
4. Memory Components:
- Storage for weights and biases
- Cache memory for intermediate computations
5. Power Supply System:
- Voltage regulators
- Power distribution network
The exact implementation can vary significantly depending on the design approach:
- Traditional CMOS-based implementations
- Analog computing approaches
- Specialized neuromorphic hardware
- Optical neural networks (using photonic components)
- Quantum implementations (still experimental)
Training is the initialization process of a neural network. A vastly simplified yet accurate analogy for this process is a me using the DUOlingo app to learn a foreign language. Duo asks me a question in the foreign language. I answer the question. If my answer is correct the button turns green and says continue then I go onto the next question. If I answer it incorrectly, the button turns red and DUO shows me where I was wrong. Then I continue to the next question.Each time I finish a section I receive points. These points accumulate overtime. I am also monitored for accuracy and time. The more often I am correct, the more points I receive.
The app has a series of sound and visual notifications to reinforce your learning. It trains you by feeding your information and having you respond. If you respond correctly, it continues the process. If I do not then the same question is asked until I give the correct answer. It is usually slipped back into the process later down the line. By the way I am a level 26 French learner and I am currently in 10th place in the diamond league.

Training a large language model is very similar. Claude 3.5 summarizes the process as follows
“The responses to prompts in large language models are statistical pattern matches, but in a highly sophisticated way. Let me break this down:
1. Pattern Recognition Process
- The model doesn't simply match exact patterns
- Instead, it uses learned probability distributions across its neural weights
- Each token (word or subword) prediction is based on complex statistical relationships
- The response is generated token by token, with each new token influenced by both the prompt and previously generated tokens
2. Statistical Generation Mechanics
- The model calculates probability distributions over its entire vocabulary
- Each word choice is influenced by:
- Learned patterns from training data
- Context from the current prompt
- Previously generated text in the response
- The statistical relationships between concepts
3. Context Integration
- The model maintains a dynamic statistical representation of:
- The current conversation state
- Relevant knowledge and patterns
- Task requirements
- Logical relationships
4. Beyond Simple Statistics
While the underlying mechanism is statistical, the outputs are more complex than simple pattern matching because:
- The model can generate novel combinations of concepts
- It can apply learned patterns to new situations
- It can maintain logical consistency across long outputs
- It can adapt its response style based on context
This is why the same prompt might generate different but equally valid responses each time - the model is sampling from probability distributions rather than following fixed rules or templates. “
The following link gives a very good overview of how this process works
https://www.ibm.com/think/topics/neural-networks
This is an image of how data is stored in a LLM. It is taken from the following source
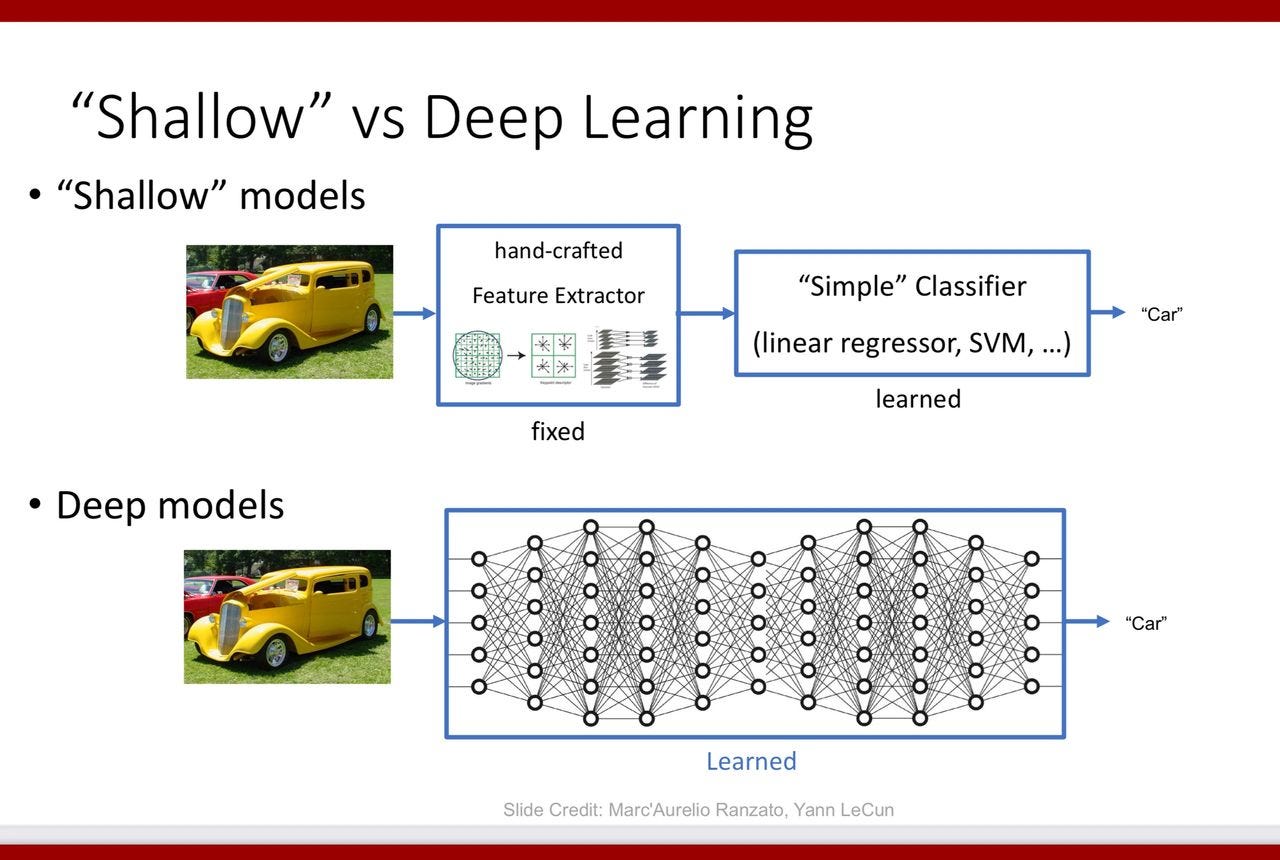
https://sites.cc.gatech.edu/classes/AY2025/cs7643_fall/assets/L1_Intro.pdf
A large language model learns. A traditional computer system follows instructions. The big difference is that a large language model responses are not as predictable as those from a traditional computing system. In addition, the large language model responses can change as more information is added. The larger the data set that the large language model is trained on the more accurate the responses. A traditional software program is going to stay within the parameters of the program and never change unless it is corrupted or updated.
Claude 3.5 on it gives a detailed description of the differences between the two architectures;
“The fundamental difference lies in how the system "learns" to perform tasks. Traditional server programming is explicit and deterministic - you write specific rules, functions, and logic paths that directly tell the system exactly what to do in each scenario. It's like building a detailed instruction manual where every possible situation has a predetermined response.
Training an LLM, on the other hand, is more like education through example. Instead of writing explicit rules, you expose the model to vast amounts of text data and let it learn patterns and relationships statistically. The model develops its own internal representations and connections, somewhat analogous to how humans learn language and concepts through exposure and pattern recognition rather than memorizing explicit rules.
A traditional server will always follow the exact logic you programmed, while an LLM develops probabilistic responses based on the patterns it has learned. This makes LLMs more flexible and able to handle novel situations, but also less predictable and potentially harder to debug compared to traditional programming.”

Implications
I. The response that you receive from your prompt is a prediction. It is not a deterministic response like you receive from a traditional computer. A response from an AI LLM is based upon patterns developed during training. The response may be incorrect , misleading and can change based upon training updates.
II. The response is partially determined by the quality of the training. If the large language model was not thoroughly trained on your topic, it may not give an appropriate response. Also, you need to be aware of potential bias that entered into the training.
III. Your prompt is the initiator of your response. The prompt is what triggers the large language model to form an answer to your request. The better the prompt, the better the response. It is critical to write a clear and concise prompt if you want the most accurate answer.. A large language model is a prediction engine. If you write an accurate and concise prompt, you will get a better prediction.
IV. Large language models act within parameters. This gives them flexibility in their response and enables them to reason. Traditional software is completely and determinedly bound by the software program. The benefit of LLM flexibility is that it can provide a very detailed and thorough response. However, the flexibility can create mistakes. It is critical to thoroughly review in a response to make sure that it is totally accurate. Therefore, if I’m going to use it for something important it is for something that I’m already familiar with so that I can have an indication of the accuracy.
V. I always remember that I am dealing with very sophisticated algorithmically enabled prediction engine. A large language model will continually evolve its thinking and processing based upon fine tuning of the training and additional technical resources.
VI. Large language models do not store your conversations. It is too expensive because everything needs to be kept in active memory. Therefore you need a strategy to store the data in a traditional computer system.
Summary
Large language, models and artificial intelligence reside in a silicon brain. It learns and develops through training. In many ways, it’s not that much different than training a dog or teaching a student. The silicone engine enables much more rapid processing of information and creation of patterns, but these patterns are based on similar neural networks that exist inside your head.
Artificial intelligence is extremely useful, but it is not the same as a traditional computer. Traditional computers are controlled by software and do not have independent agency. One of the main purposes of artificial intelligence is to create autonomous agency so that bots and other AI enabled devices can perform jobs that are now done by people. This gives you less control than a traditional computer system, but the ability to perform far more functions.
I use large language models quite frequently. I am exploring ways to achieve more benefits from them. However, I need to realize that I am dealing with a system that operates with in parameters and without deterministic control. Therefore, I need to treat the results differently than I do information generated by a traditional computer system. We’re dealing with a brain that is designed to process information like a human. This gives it advantages and disadvantages that you need to keep in mind when you’re using it.